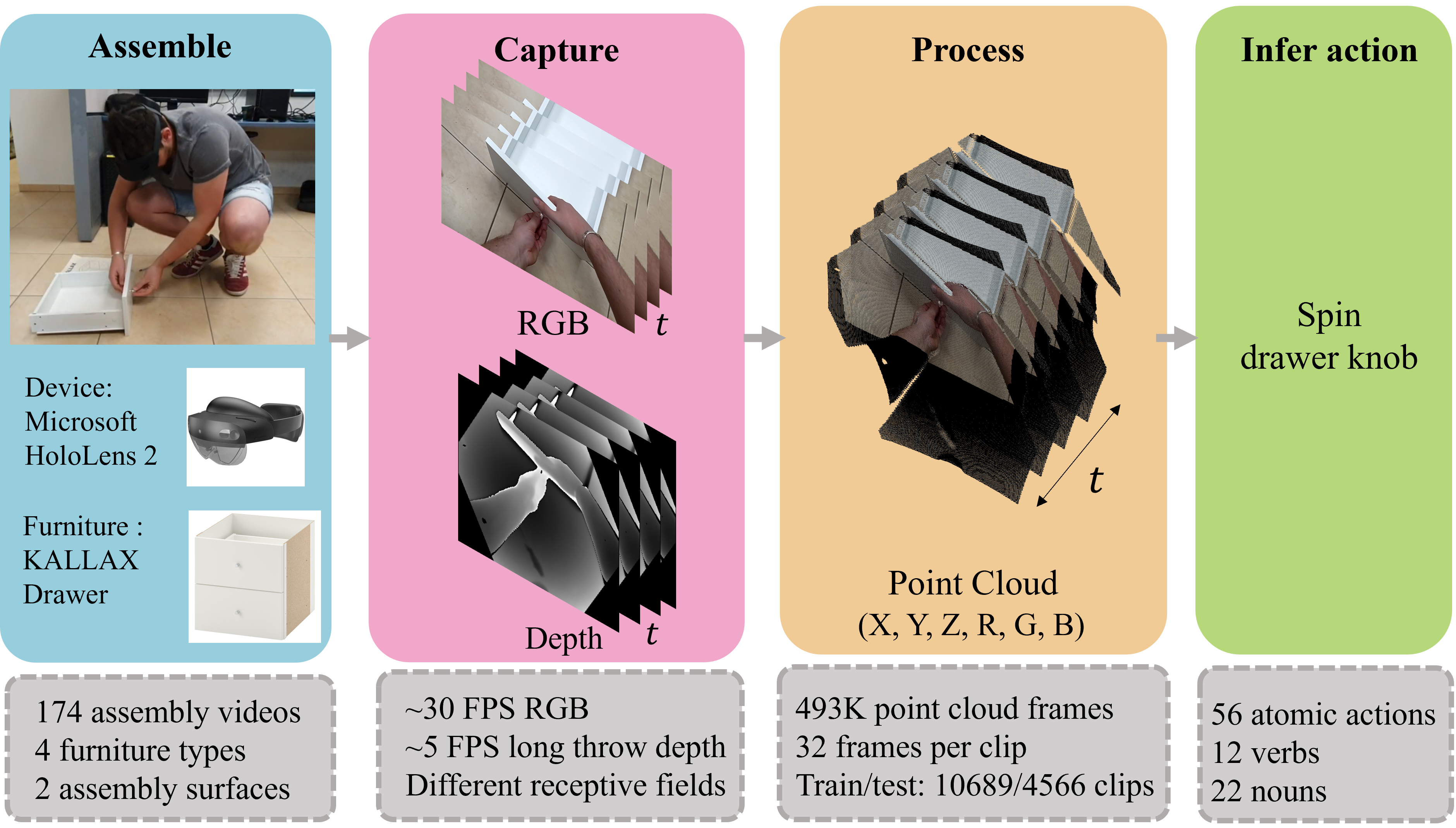
We propose a novel dataset for ego-view 3D point cloud action recognition. While there has been extensive research on understanding human actions in RGB videos in recent years, the exploration of its 3D point cloud counterpart has been relatively limited. Furthermore, RGB ego-view datasets are rapidly growing, however, 3D point cloud ego-view datasets are scarce at best. Existing 3D datasets are limited in several ways, some include actions that are distinguishable by full-body motion while others use a distant static sensor that hinders the recognition of small objects. We introduce a new point cloud action recognition dataset-the *IKEA Ego 3D dataset*. It includes sequences of point clouds captured from an ego-view using a HoloLens 2 device. The dataset consists of approximately 493k frames and 56 classes of intricate furniture assembly actions of four different furniture types. We evaluate the performance of various state-of-the-art 3D action recognition methods on the proposed dataset and show that it is very challenging.
This work was funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 893465. We also thank the NVIDIA Academic Hardware Grant Program for providing an A5000 GPU.
@article{benshabat2024ikeaego3d,
title={IKEA Ego 3D Dataset: Understanding furniture assembly actions from ego-view 3D Point Clouds},
author={Ben-Shabat, Yizhak and Paul, Jonathan and Segev, Eviatar and Shrout, Oren and Gould, Stephen},
journal={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
year={2024}
}